Packets, Drop by Drop

I originally started writing this blog to document all the tricky bugs I encountered, and google couldn't answer.
My, did I ever find one. And it wasn't one of the issues that makes you go beat yourself for not figuring it out sooner.
Network, gross work
We had a simple change in our cloud infrastructure. We were changing our routers. We let the network people do their magic, and after a few seconds of network downtime all our cloud customer traffic uses the new router pair. Simple L3 stuff, nothing that affects our configs or our system. Right?
Immediately after the router change, we started seeing packet loss. It was quite significant packet loss, around 1-5%. This problem was traced to the routers. I think a router MTU config helped here, and the situation got much better.
The packet loss didn't go away though. First it was tricky to see, but we had a consistent 0,01% - 0,1% packet loss when we tested. We don't have long term statistics of our packet loss, so we couldn't be 100% sure this hadn't happened before. Our customers reported that TCP transfer speeds had dropped, which did indicate that this was a new issue. This level of packet loss was large enough to cause TCP window sizes to fall, and kill network throughput.
Debugging
I will spare you a lot of gory details and dead-ends. All in all, we had the problem for a week and a half.
First of all, we tired using iperf to verify the problem. It took a while for us to replicate this, since testing iperf against an external service seemed to work nicely, with no performance problems. Then we noticed that it's actually only traffic from the internet towards the cloud that's affected. Outgoing traffic had no problem. We reversed the iperf test, and sure enough, it got slow.
My first thought was that it must be the router that drops them. I found a decent test that consistently showed the problem and let me debug it. From outside the cloud I ran a
ping -i 0.01 -c 4000 virtual_machine_ip
This usually dropped at least one packet. Iperf3 was better at actually seeing the problem, but this way I could count packets easier.
Then on the first interface on our network node hypervisor where the packets came in I ran a tcpdump
tcpdump -en -i interface_name icmp and host virtual_machine_ip
I had just lauched the VM, so I knew that my traffic was likely the only thing going there. This tcpdump command shows all icmp traffic, so if you ever try this yourself, be aware that the output also contains ping replies in the packet counts.
With this I could confirm that the packets do reach our network hypervisor, and I couldn't blame other people. sigh
So at this point we knew that
- A router change, which shouldn't have affected us at all, started causing packet loss.
- It only affects traffic in one direction.
- The traffic is not dropped by the network switching/routing layer.
We did know one thing more. With the router change, the HA protocol changed from HSRP to VRRP. Now, this seems relevant, but spoilers: while it was probably the cause, it was only an indirect cause, so it lead us on some wild goose chases.
Digging deeper
For the next part, I think we'll need some visual aids. This is the network setup of our OpenStack network nodes. I'm not sure it this is correctly drawn according to standards, but you get the point.
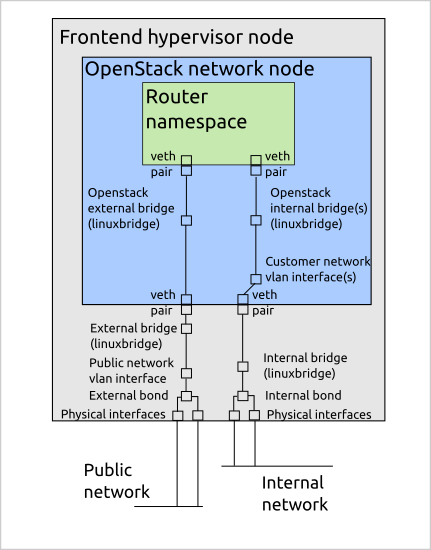
As you see, there are 8 interfaces the packet will travel through before it comes to the router namespace. We also have a very similar setup for both internal and public networks, but packets only get dropped in one direction. This was the router side, it happened after the router change. It must be something to do with that.
First, do all the packages get to the router namespace? Tcpdump says no. How far does it get? Apparently to the namespace's paired veth interface. This helped debugging a bit, since it was enough to ping the virtual router's ip to replicate the problem. This ruled out a lot of components.
At this point my knowledge about Linux network internals started running out. Shouldn't a veth pair be just a... tube in lieu of a better word? That shouldn't drop anything.
Here is where I spent most of my debugging (and reading about Linux networking) time. How good is the Linux kernel and how good are the network device drivers? Do they do something like zero-copy and the packet is actually still on the network card, but gets pushed out due to something? Or, since the network nodes run a lot of OpenStack routers, and we mainly saw problems with over 64 routers on a network node, is there a MAC address limit somewhere? Are the VRRP mulitcast packets causing some strange issues? How about interface txqueuelen? I tried looking into all of these, with no success.
A large part of the problem was that tcpdump can't catch the dropping packets. I had no way of seeing if there were any patterns in dropped packets.
Dropwatch
After trying and trying to find out how to get a hold of those packets, I found a blog post about dropwatch.
Finally a thread I can pull on. I installed and ran dropwatch on the network node. The output of the tool is low-level to say the least.
4 drops at icmp_rcv+135 (0xffffffff815e7355)
302 drops at enqueue_to_backlog+9c (0xffffffff8156e95c)
3 drops at tcp_v4_rcv+87 (0xffffffff815d66a7)
77 drops at ip_rcv_finish+1b4 (0xffffffff815b0544)
6 drops at ip6_mc_input+1ad (0xffffffff8162941d)
19 drops at arp_rcv+b8 (0xffffffff815e5318)
1548 drops at ip_rcv_finish+1b4 (0xffffffff815b0544)
860 drops at enqueue_to_backlog+9c (0xffffffff8156e95c)
4 drops at icmp_rcv+135 (0xffffffff815e7355)
3 drops at tcp_v4_rcv+87 (0xffffffff815d66a7)
82 drops at ip_rcv_finish+1b4 (0xffffffff815b0544)
3 drops at ip6_mc_input+1ad (0xffffffff8162941d)
4 drops at arp_rcv+b8 (0xffffffff815e5318)
1 drops at __brk_limit+1df94778 (0xffffffffa0354778)
558 drops at enqueue_to_backlog+9c (0xffffffff8156e95c)
There were several instances of these, which looked a bit suspicious.
558 drops at enqueue_to_backlog+9c (0xffffffff8156e95c)
Searching for that function name took me to a this really good network guide, and the almost casual mention of this sysctl parameter
net.core.netdev_max_backlog
At this point I had tried tens of things, and didn't have much hope that this would fix the issue, but I increased the value from the default of 1000 to 3000 to see what happens.
No. More. Packet. Loss.
A week and a half of work, and this almost disappointing looking sysctl parameter fixed it? Don't get me wrong, I was ecstatic. The thing that frustrated me was that the problem appeared with the router change, which really threw of the debugging.
My current theory on why this happened is that the the added background level of VRRP traffic pushed this limit consistently over the top. We had probably had low levels of packet loss in some cases earlier too, but this made it consistent.
TL;DR;
If you have packet loss in similar situations
- Use dropwatch for debugging. It seems awesome.
- Try setting net.core.netdev_max_backlog to something sensible like 65536.
Geek. Product Owner @CSCfi
